

There’s a popular breakfast dish in Philadelphia known as scrapple, which consists of pork scraps and trimmings – all the leftover parts of meat after butchering that could not be used or sold elsewhere to avoid waste. An AI project that we presented last year reminds me of scrapple because its goal is the same – leave no waste and utilize every bit of computing power of a NVIDIA Jetson Nano. This is accomplished by running two separate machine learning models on a Jetson Nano – one on the GPU and one on the CPU.
We wanted to use machine learning to count automobiles and predict the current traffic conditions. We knew that we could easily count cars with one of our favorite computer vision projects, OpenDataCam. This open source tool is optimized to run on CUDA GPU hardware such as the NVIDIA Jetson series.
We also knew we needed a little bit more AI to run a separate model that is fed from the real time data coming from OpenDataCam. We could have used a Raspberry Pi for this less resource intensive model, but then we realized that our Jetson Nano running OpenDataCam has a perfectly good CPU (a quad-core ARM Cortex-A57 no less) basically sitting idle. So like the aforementioned scrapple, we did not let any compute power go to waste.
For the model running on the CPU, we chose Edge Impulse which allows AI deployment on a variety of edge devices from GPUs to microcontrollers – perfect for our use case.
Since this is a fairly unique and useful combination, we decided to write about it here and now, because it was originally presented to a somewhat limited audience. You can use this project as a template for your own CPU + GPU AI application! The repository for this project is located here if you want to try it out for yourself.
IoT on the edge
Our project and all of its services run completely on the edge and do all of their data generation and predictions without sending anything to the cloud:
We’re using the balena platform to make provisioning, updating and troubleshooting our devices easy. It also makes it trivial to deploy to more than one device (or tens of thousands!)
OpenDataCam uses an onboard object detection library (YOLO) to output data (not images) and provides a local API.
Edge Impulse consumes the data from OpenDataCam’s API and uses its onboard model to create our traffic prediction inference.
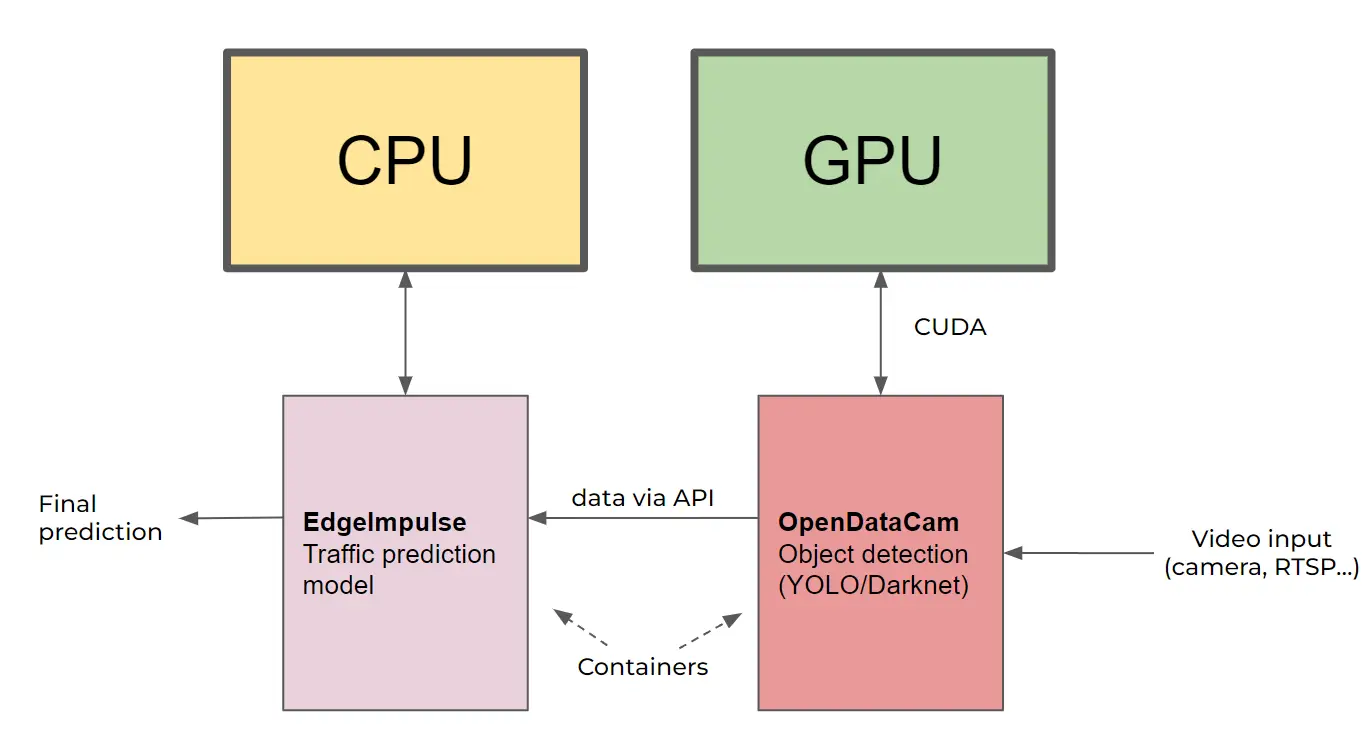
How it works
First we aimed an IP camera out the window at a relatively busy street, and fed that into an unmodified version of OpenDataCam. We then used the “counter” feature to draw two lines on the screen which allows OpenDataCam to count how many cars pass between them when the “recording” feature is engaged. (This is a data recording feature, not a traditional video recording feature.) Since we know the physical distance between the two lines, we can calculate speed.

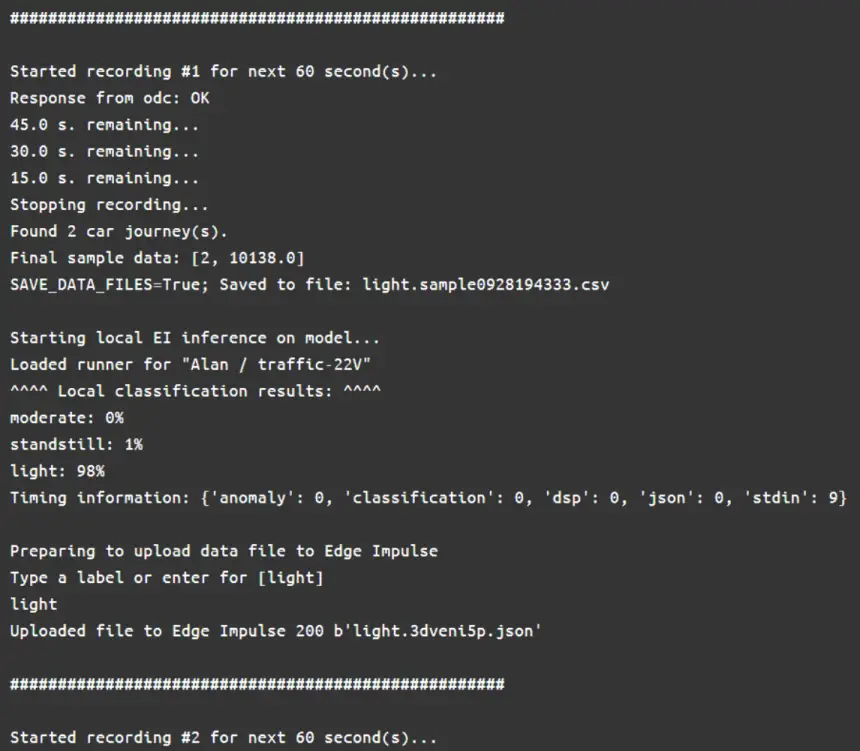
Our custom code lives in the Edge Impulse (“ei”) container and utilizes the “Edge Impulse for Linux” Python SDK. This code calls the OpenDataCam API to repeatedly record 60 seconds of traffic data. This data is then analyzed to determine the number of cars and each car’s average speed. That information is then fed to the on-device Edge Impulse model which performs an inference and provides a prediction of the current traffic level (such as “light”, “moderate”, or “heavy”). In addition, there is an option to re-label inaccurate predictions and upload them back to Edge Impulse for re-training the model to increase its accuracy. Here’s some example output from our code:
Edge Impulse Setup
Edge Impulse provides intuitive tools for building and training a model (which they call “impulses”). We chose a “time series” template and our input data was “car count” and “average speed”. Our learning block uses the Keras classification algorithm and our output consisted of three features that describe the traffic prediction: “light”, “moderate” and “standstill”)
Balena features
In addition to the ease of device provisioning, deployment, and management mentioned earlier, the balena platform offers additional features that make it a great companion for Edge Impulse projects such as this.
Device variables allow you to make changes to the configuration of the project from the balenaCloud dashboard rather than having to directly access the device or its code. For instance, you can place the project into demo mode if no camera is available or change the sampling interval by setting variables. We also use variables to set the API key for Edge Impulse, making it simple to update these parameters if they change.
Since the balena platform runs containers, we are able to easily separate our application into functional pieces. All of our code and the Edge Impulse SDK live in their own container, so we don’t interfere with the Python versions and dependencies in the OpenDataCam container.
Because containers are defined by Dockerfiles, we have a clearly defined startup process for each container. The Edge Impulse container runs a script at startup that grabs a new version of the traffic prediction model (if available.) This way, the device is always using the most up to date model, incorporating any re-training that may have taken place.
Results and accuracy

Ultimately, our traffic prediction model’s accuracy was poor, at around 33% – doing a coin toss would probably yield better results. It’s likely that further fine tuning of the model would have improved it significantly. However, the point of this exercise was to show how we could easily run two models on the device at the same time – and run them on separate elements of the hardware that they were optimized for.
To watch a video of the full presentation, click below:

Final thoughts
The combination of a CUDA-optimized vision model feeding a data-driven Edge Impulse model, both running comfortably on the same device is compelling. The use of the balena platform to deploy, manage, and update the project streamlines it even more.
Do you have a project that would benefit from a similar combination of models? Have you tried this project out or adapted it for your own use case? As always, we welcome feedback in the discussion below or in our forums!